İsimsiz genom verilerinden kimliğin tespit edilmesi kimi neden ürküttü?
Yayın Tarihi: 01.02.2013 , 22:29 Güncelleme Tarihi: 08.05.2021 , 00:49
Genom dizilemenin ucuzlamasıyla birlikte, son yıllarda çeşitli araştırma kurumları farklı toplumlardan çok sayıda bireyin genomunu dizilemekte. İnsan sağlığı, genetiği ve evrimini anlamak için çok değerli bir kaynak olan bu genom verileri, herkese açık biçimde internet ortamında bulunuyor. Bu projelerin en ünlüsü, Afrika'dan Amerika'ya kadar farklı bölgelerde 14 toplumdan 1092 bireyin genomunun dizilendiği 1000 Genom Projesi’ydi. Bu çalışma için DNA örnekleri gönüllülerden anonimlik garantisiyle toplanmış, bireylere, genetik verilerinin bilimsel amaçlarla kullanılacağı ve yayımlanacağı, ancak kimliklerinin açık edilmeyeceği temin edilmişti.
Geçtiğimiz hafta Science dergisinde yayınlanan bir araştırma bu teminatın umulduğu kadar güvenilir olmayabileceğine işaret etti.
Y kromozomuyla soyadı tahmini
ABD'nin Whitehead Enstitüsü'nde çalışan ve aralarında eski bir bilgisayar korsanının da yer aldığı bir grup araştırmacı, 1000 Genom Projesi'ndeki Avrupa kökenli Amerikalılara ait isimsiz DNA dizisi verilerinin kimden geldiğini bulup bulamayacaklarını anlamak için bir araştırma başlattılar. Ekip, projedeki genom dizilerini, internet üzerinden erişilebilen aile soyağacı veri tabanlarındaki verilerle karşılaştırdı.
ABD'de giderek popülerleşen bu aile soyağacı veri tabanları şu şekilde işliyor: Bireyler para ödeyerek DNA’larını bir şirkete diziletiyorlar. Sonra kimlik bilgilerini ve DNA bilgilerini bu veri tabanlarına giriyorlar. Amaçlardan biri, tanımadıkları akrabalarını bulmak ve aile geçmişlerini ortaya çıkarmak.
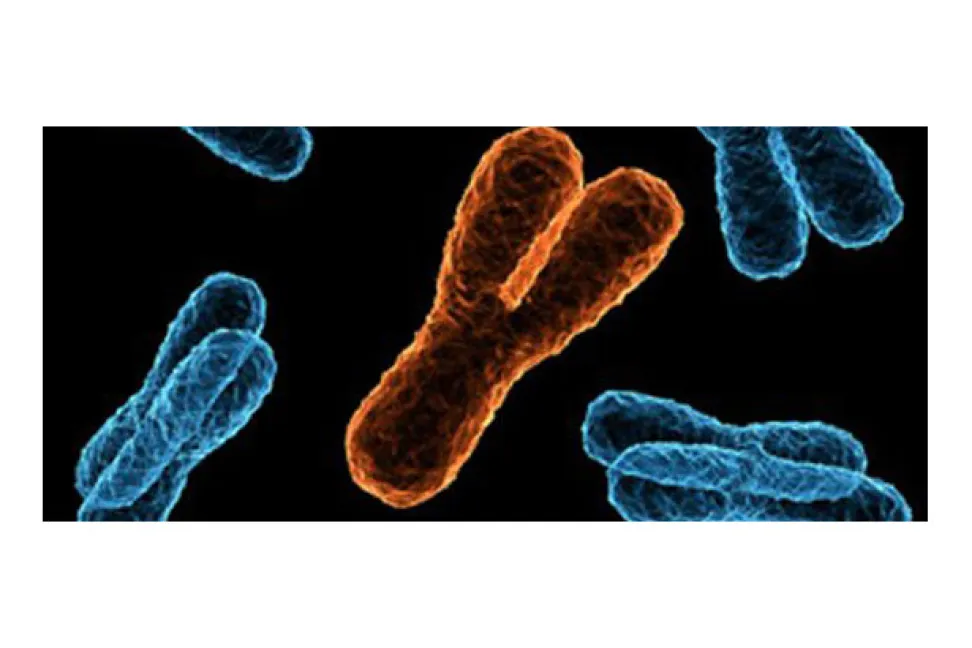
Araştırmacılar, farklı bireylere ait yüzbinlerce Y kromozomunun bilgisini barındıran iki veri tabanı kullandılar. Kromozom hücre çekirdeğinde bulunan uzun DNA moleküllerinin adı. Y kromozomu da yalnız erkeklerde bulunan uzun DNA molekülü (Şekil 1).
Çalışma açısından bu kromozomun kullanımı önemliydi: Günümüzde pek çok toplumda soyadı babadan çocuklara geçmekte. Y kromozomu da babadan geçtiği için, bu kromozomun dizisine bakarak bir kişinin soyadını tahmin etmek mümkün.
Diyelim ki A kişisinin babasının amcasının oğlunun oğlu B kişisi veri tabanına kayıtlı olsun. Eğer ailede tüm babalar biyolojik baba ise, A ile B'nin Y kromozomu çok benzer olacaktır. Eğer ailede kimse soyadını değiştirmediyse A ile B'nin soyadları da aynı olacaktır.
ABD'de bu yöntemi kullanan evlat edinilmiş çocukların biyolojik akrabalarına, oradan da biyolojik babalarına ulaşabildikleri geçtiğimiz yıllarda basına yansımıştı (Şekil 2).
Makale yazarları da aynı yöntemle, 1000 Genom Projesi'ne DNA'sını vermiş isimsiz bireylerin Y kromozomu dizilerini veri tabanlarıyla karşılaştırarak katkıcıların soyadlarını tahmin ettiler. Daha sonra, yine bu anonim kişilere ait veri tabanlarında yer alan yaş gibi bilgileri kullanarak aynı soyada sahip binlerce birey arasından, projeye DNA veren gönüllülerin kimliklerine ulaştılar. Ekip bu şekilde, 50 bireyin kimliğini tespit edebildiğini ve %12 başarı oranı yakaladığını açıkladı.
ABD'de asıl sorun: Özel sigorta şirketleri
Elbette araştırma sonucunda bulunan kimlikler yayımlanmadı. Dahası, bu kimliklere ulaşmayı kolaylaştıran veriler makale yayımlanmadan önce kısıtlandı dolayısıyla şu anda aynı yolla söz konusu verilere ulaşmak mümkün değil. Yine de makale, genetik verilerin kamuya açık hale getirilmesi hakkında hararetli bir tartışma başlattı.
Sağlık hizmetlerinin çok pahalı olduğu ve sağlık güvencesinin asıl olarak özel şirketler eliyle yürütüldüğü ABD'de birçok kesim, sigorta şirketlerinin müşterilerin genetik bilgilerini edinerek bunu kötüye kullanacağından korkuyor.
ABD'de patronların ve sağlık sigortası şirketlerinin bireylere genetik verilerini kullanarak ayrımcılık uygulaması 2008 yılında “Genetic Information Nondiscrimination Act” (GINA) isimli yasayla yasaklanmıştı. Ancak uzmanlar, GINA’nın yalnızca sağlık sigortasını kapsadığına ve yaşam sigortası, sakatlık sigortası gibi alternatif hizmetlerde ayrımcılığı açıkta bıraktığına dikkat çekiyorlar.
Dolayısıyla şu anda ABD'de tartışılan olumsuz senaryolardan biri, DNA'sını paylaşan bireylerin kamu veri tabanlarına konan genomlarının örneğin yaşam sigortası şirketlerince tespit edilmesi, bu genomlarda hastalık riskini artırıcı genetik etmenler aranması, ve nihayetinde kanser gibi hastalıkların riskini artıran genetik özelliklere sahip bireylere daha yüksek sigorta primi uygulanması...
Nitekim sigara kullanımı, beslenme veya idman gibi çevresel etmenlerin yanı sıra genetik özellikler de kanser, kalp ya da şeker hastalığı gibi sağlık sorunlarının ortaya çıkma ihtimalini etkileyebiliyor.
Genetik verilerin korunması niye önemli?
Elbette herkes için parasız sağlık hizmeti, bu sorunun aşılması için anlamlı ve kestirme bir yol olabilir. Ancak, hastalık ihtimali ya da akrabalık gibi bilgiler barındıran genetik verilerin, özel sigorta şirketleri dışında da, bireylerin istemediği biçimde kullanılması ihtimal dahilinde. Ayrımcılığın yaygın olduğu günümüz sınıflı toplumlarında, bireylerin bu tip bilgilerini başkalarıyla paylaşmak istemeyecekleri durumlar ortaya çıkabilir.
Öte yandan makalenin yazarları, anonim genetik verilerin açık veri tabanlarında paylaşılmasının ve dünya çapında araştırmacılarca yeniden kullanılmasının önemine dikkat çekiyorlar. Bu tür veriler, genetik hastalıkların anlaşılmasından insan evriminin incelenmesine kadar çok geniş kapsamdaki araştırmalar için temel malzeme. Örneğin 1000 Genom Projesi’nin ilk çözümlemeleri, her bir insanın genomunda yüzlerce zararlı mutasyon olduğunu göstermişti.
Bu tip geniş çaplı projelere yatırım yapamayan Türkiye gibi ülkelerdeki araştırmacılar için de verilerin kamuya açık olmasının ayrıca önemi var. Makale yazarları da sorunun çözümünün genom verilerinin saklanmasında olmadığını vurguluyorlar. Aynı zamanda, genetik veri kullanımının yasal koşullarının netleştirilmesi ve genom dizileme deneylerine katılan gönüllülerin daha iyi bilgilendirilmesi çağrısında da bulunuyorlar.
Türkiye'de durum ne?
Aile soyağacı veri tabanlarının kullanımı Türkiye'de yaygın olmadığı için, Türkiye’de yürüyen az sayıda genom projesine katkıda bulunan gönüllüler için benzer bir tehlike söz konusu değil. Öte yandan, önümüzdeki yıllarda Türkiye’de de DNA dizilemenin daha yaygın hale gelmesi ve bu verilerin yayımlanması beklenebilir.
Bu açıdan Türkiye’de yasal bir boşluk olduğu da dikkat çekiyor. Nitekim genetik veri kullanımına değinen "Kişisel Verilerin Korunması Hakkında Kanun Tasarısı" ilk defa 10 yıl önce hazırlanmış olmasına rağmen halen yasalaşmış değil.
Bu makalenin kısa hali soL Gazetesi'nin 31 Ocak 2013 sayısında, sayfa 13'te "İsimsiz genom verilerinden kimlik tespiti" başlığıyla yayınlandı.
BilimsoL ekibinden Mehmet Somel hazırladı.
facebook.com/BilimsoL
twitter.com/BilimsoL
İlgili makaleler:
Gymrek, 2013, Identifying personal genomes by surname inference, Science, http://www.sciencemag.org/content/339/6117/321.long.
Schultz, 2013, It's Legal For Some Insurers To Discriminate Based On Genes, NPR, http://www.npr.org/blogs/health/2013/01/17/169634045/some-types-of-insur....
soL YZ Beta, soL’un geliştirdiği ve soL arşiviyle çalışan bir yapay zeka robotudur. Kullanımı, soL abonelerine açıktır.